")
Cloud migration is becoming a trend as cloud environments are scalable, reliable, and highly available. It gives everyone access to enterprise-class technology and allows businesses to act faster. One of the projects we worked on this year was to migrate our customer’s content from Perceptive Contents, an Enterprise Content Management and workflow suite from Hyland, to Box. Due to Perceptive Contents’ document structure and organization, the traditional lift and shift process was deemed ineffective and we sought a different approach. In this blog, I will discuss the general architecture of migration projects and the considerations and decisions I had to make due to the unique characteristics of the system.
Standard migration architecture
The first step to all migration projects is to perform a content inventory to identify the documents, files, and information that you want to move. Organizations must have a good understanding of the documents they want to transfer before the migration. Content discovery can be challenging as content could be stored in multiple places and have multiple owners with different priorities. Once the content has been identified, we can extract the content from the system.
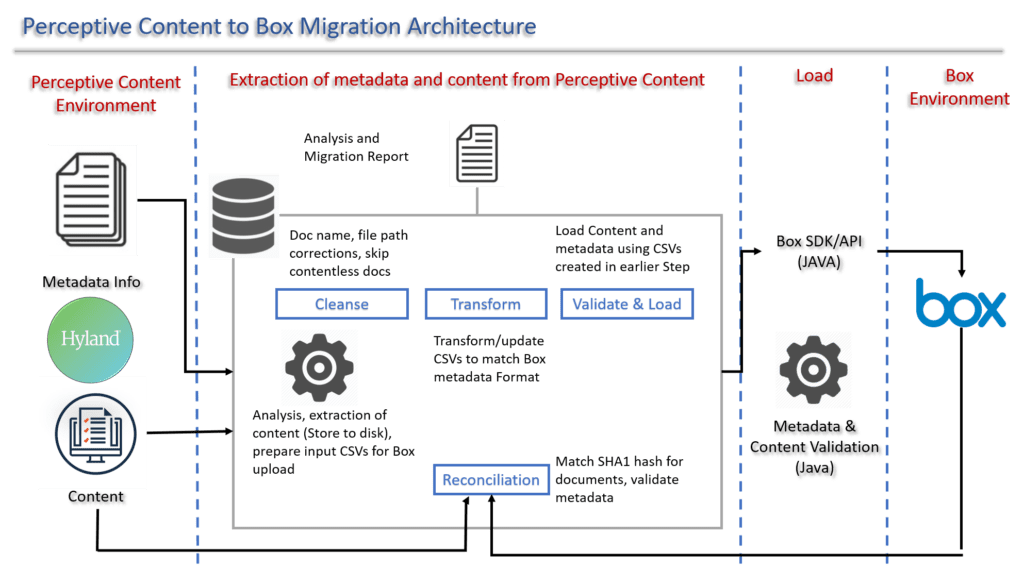
During the content and metadata extraction stage, contents and metadata information are processed as shown in the above diagram. The document information needs to be cleansed to fit the Box’s limitation. Then the metadata needs to be transformed to the most fitting data type in Box. Data and contents are then uploaded to Box.
At last, the documents are validated by checking report files/database consisting of information on uploaded BoxFile and comparing the Box’s auto-generated SHA-1 hash value to SHA-1 of the local file to ensure the integrity of the data
Perceptive Contents
Perceptive Content is a scalable content services platform that manages the entire content lifecycle, from capture to disposition. Consequently, the platform operates with its own document structure and organization and this makes integration of other systems difficult. For this reason, we were unable to implement a lift and shift approach for the cloud migration from Perceptive Content. The unique features of Perceptive Content and the considerations and decisions we made to overcome the issues are as follows.
Tool
For the development, we considered between REST API and Perceptive iScript for extracting data from Perceptive Content. Perceptive Contents iScript is a custom automation engine that allows you to programmatically complete tasks, make decisions, and communicate with other systems from Perceptive Content. REST API offered endpoints that will simplify the development; however, we chose iScript over it due to the drawback of additional consumption costs.
Automated naming and Automated Folding
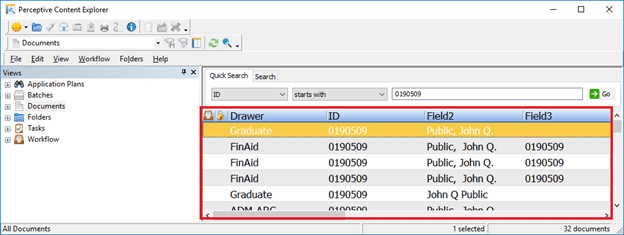
In Perceptive Content, drawers provide the first hierarchical level of organization for documents. A drawer is used to separate documents into logical categories. As shown in the image, each document is assigned to a drawer with no additional level of organization. Then, the user must filter with metadata to find the documents. As document names in Perceptive Contents are auto-generated unique ids, enforcing the lift and shift approach would result in a jumble of files impossible to identify.
Our solution to overcome this problem involves automated naming and folding of documents. Clients can define the name and path of the documents using existing metadata values. The file names and paths built during the extraction phase then are used to upload the file to its destination system.
Metadata
Every document in Perceptive Content has five general properties fields, named field1, field2, and so on. Users can assign an alias to each field in each drawer to give meanings to the general properties. On the other hand, you can also map up to five custom properties to each document type, which is a document key that categorizes a document according to a predefined list of values. Also, the data types of Perceptive Content’s metadata were different from Box. For example, Box only allows a specific format (RFC3339) for date data type; whereas, it is stored as six digit integers consisting of years, months, and days in the originating system.
For our solution for migration metadata, we used a map to define the field names, values, and data type of value. This way, the client can only have the values that are relevant to their current workflows transferred and dispose of the outdated fields that are no longer in use. We first extracted the values from the system according to the name and patterns specified on the map, then transformed the values to the type that works with Box.
Multi-file document
Perceptive Contents allows multi-file documents, a document containing several files with the metadata constituting one multi-file document. Each page of the document, except for files with TIF extensions, is a single file. As for the TIF files, multipage TIFF files are stored as separate pages to enable the preview feature in Perceptive Content.
When extracting the content, files are extracted page by page into separate files. TIF files are then merged to form a single multi-page file with external software. To keep all files from a document together, a naming scheme that includes the document title (or other unique combination of metadata fields) and a two-digit sequence number was used. This keeps files of the same document stay adjacent to each other when sorted in alphabetical order in Box.
Annotations
Perceptive Contents allows end-users to add annotations to images. In this instance, the Customer chose to include migrating the annotations. Annotation was heavily used during the workflow to signify the approved step. Consequently, the annotations were burned into the images during the extraction process.
Conclusion
Cloud migration is gaining popularity, but you must think about the benefits it brings to your company before following the trend. In this case, Cloud migration from Perceptive Contents to Box was not only to transfer contents from one place to another but also to standardize the files to make them compatible with other integration and to brace for later use.