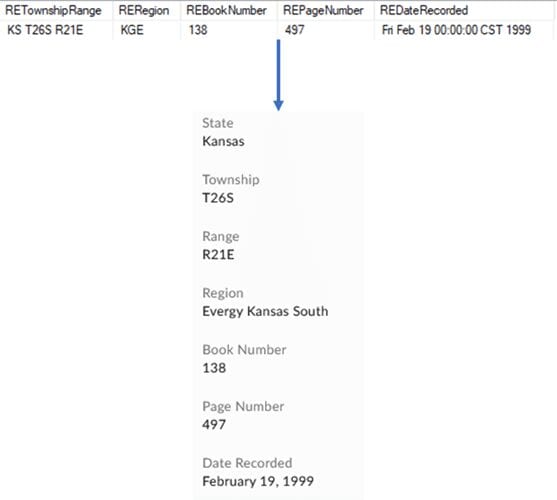
")

In today’s dynamic business landscape, efficient document management is crucial for organizations seeking streamlined workflows

TORONTO, CANADA. On Wednesday, February 7th, Reva Solutions attended the 2024 OpenText Summit as a

One of our customers, a user of Zendesk’s help desk ticketing system frequently needs to
We had the opportunity to work with a Fortune 1000 company’s commercial loan business unit